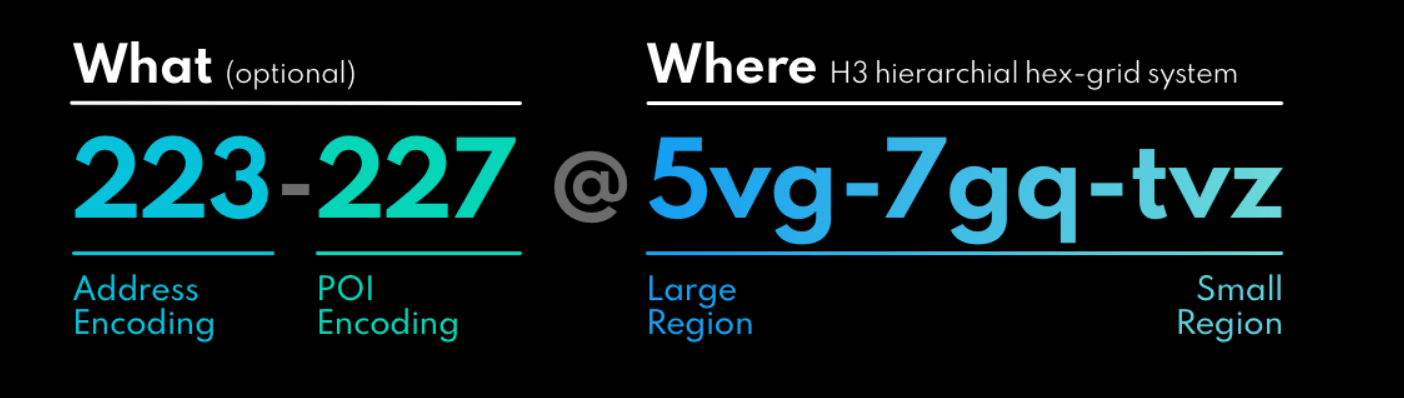This section is authenticating your Google Drive and download/reading in the appropriate files from their respective Google Drive locations
# special libraries to allow file access
from google.colab import drive as mountGoogleDrive
from pydrive.auth import GoogleAuth
from pydrive.drive import GoogleDrive
from google.colab import auth
from oauth2client.client import GoogleCredentials
import pandas as pd
# These commands allow you to read directly from SafeGraph's public GoogleDrive containing Census Data and Sample Data
auth.authenticate_user() # Authenticate and create the PyDrive client.
gauth = GoogleAuth()
gauth.credentials = GoogleCredentials.get_application_default()
drive = GoogleDrive(gauth)
print("You are fully authenticated and can edit and re-run everything in the notebook. Enjoy!")
Expected outcome:
You are fully authenticated and can edit and re-run everything in the notebook. Enjoy!
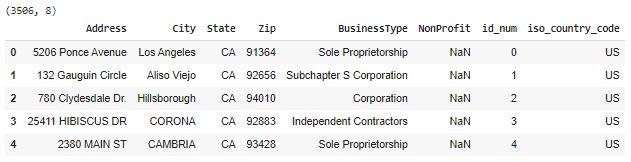
places_df = pd_read_csv_drive(get_drive_id('business_3k'), drive=drive, dtype={'Zip':str}) # It is very important to keep columns like Zip and NAICS as string to make sure Pandas doesn't mistake it for integers and drop leading zeros
places_df.head()
Install the Placekey library using Pip and then import it
!pip install placekey
import numpy as np
import json
from placekey.api import PlacekeyAPI
Add your API Key below
Note:
You will need to add your own API key in the cell below for this tutorial to work (Free and Easy!)
The commented out file path variable called data_path is for non CoLab use
Setting dtypes is super important when working with address data to ensure leading zeros don't lead to inaccurate data
In the cell below you are telling the API, in a JSON format, which columns in your dataframe relate to the API query. Note: Country 'US' is hardcoded below. While it is not required, the more data you give Placekey, the easier the match process will be.
orig_df = places_df.copy() #Only required because of auto read in for CoLab*
The optional step below is only if you don't already have a unique identifier for your data
The unique identifier ensures that we can remerge on the correct rows later
# Optional
li = []
for x in range(orig_df.shape[0]):
li.append(f"{x}")
orig_df['id_num'] = li
orig_df['iso_country_code'] = 'US'
print(orig_df.shape)
orig_df.head()
query_id_col = "id_num" # this column in your data should be unique for every row
column_map = {query_id_col:"query_id",
"Address": "street_address",
"City": "city",
"State": "region",
"Zip": "postal_code",
"iso_country_code": "iso_country_code",
# "LAT": "latitude",
# "LON": "longitude"
}
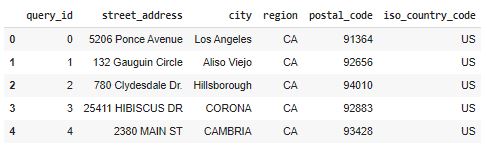
df_for_api = orig_df.rename(columns=column_map)
cols = list(column_map.values())
df_for_api = df_for_api[cols]
df_for_api.head()
Check for Null, None, NaN, etc rows
This will alert you to any incomplete data and help you determine if you should drop those rows or not.
For instance, if you notice you have 5,000 rows missing a latitude, you could save yourself some time by dropping those columns (that was not the case for this data)
df_clean = df_for_api.copy()
possible_bad_values = ["", " ", "null", "Null", "None", "nan", "Nan"] # Any other dirty data you need to clean up?
for bad_value in possible_bad_values:
df_clean = df_clean.replace(to_replace=bad_value, value=np.nan)
print("FYI data missing from at least 1 column in the following number of rows:")
print(df_clean.shape[0] - df_clean.dropna().shape[0])
print("Some examples of rows with missing data")
df_clean[df_clean.isnull().any(axis=1)].head()
data_jsoned = json.loads(df_clean.to_json(orient="records"))
print("number of records: ", len(data_jsoned))
print("example record:")
print(data_jsoned[0])
Check Placekey Request
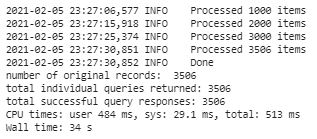
The cell below will query your first input to ensure everything is formatted correctly before moving on to the batch processing
Warning: this next step takes 1-2min to run in completion
This file is 3.5k rows of data processed in batches of 1,000 rows at a time
While the code runs, you can read up on how Placekey tiers the matching process:
Matching Behaviour
Our matching algorithm tries a few different queries, sequentially, and returns the best match of the first query to return with high enough score to feel assured it's a true match. Here are the queries it does, in order:
If the address you've sent in is valid, then we search for a POI at that address placekey with a name that exactly case-insensitively matches the location_name you've sent in. If this does not match (or if the address you sent in wasn't valid) but you've sent in a latitude and longitude with your query, then we search for that location_name and a fuzzy street address within 1km of your coordinates. If this still does not match but you've sent in a postal code, then we search specifically for a POI in that postal code and look for a location_name match and a fuzzy street address match If none of the above match and you have sent in a city and a region, then we require a strict match on city/region, a match on poi name, and a fuzzy match on street address. Finally, if none of the above match, we stop searching for POI and perform an address match.
%%time
responses = pk_api.lookup_placekeys(data_jsoned,
strict_address_match=False,
strict_name_match=False,
verbose=True)
def clean_api_responses(data_jsoned, responses):
print("number of original records: ", len(data_jsoned))
print("total individual queries returned:", len(responses))
# filter out invalid responses
responses_cleaned = [resp for resp in responses if 'query_id' in resp]
print("total successful query responses:", len(responses_cleaned))
return(responses_cleaned)
responses_cleaned = clean_api_responses(data_jsoned, responses)
df_placekeys = pd.read_json(json.dumps(responses_cleaned), dtype={'query_id':str})
df_placekeys.head(10)
Remerge on your unique ID
You can now see your newly added Placekeys as well as an 'error' column that will leave some form of breadcrumbs to allow your to troubleshoot if the query comes back blank.
Error Codes
We use standard HTTP status codes to communicate success or failure.
Code Title Description 200 OK The request was successful
400 Bad Request The request is invalid. Read the message or error fields in the response for information on how to correct it.
401 Unauthorized Your API key is invalid. Check that you haven't removed it and that you've used the right header: apikey
429 Too Many Requests You have exceeded the permitted rate-limit. Check your dashboard to see how many requests have been made recently.
50x Internal Server Error An error occurred within our API. If this occurs, you may need to contact us to resolve
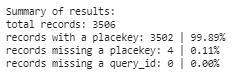
print("Summary of results:")
total_recs = df_join_placekey.shape[0]
print("total records:", total_recs)
print("records with a placekey: {0} | {1:.2f}%".format(df_join_placekey[~df_join_placekey.placekey.isnull()].shape[0], df_join_placekey[~df_join_placekey.placekey.isnull()].shape[0]*100/total_recs))
print("records missing a placekey: {0} | {1:.2f}% ".format(df_join_placekey[df_join_placekey.placekey.isnull()].shape[0], df_join_placekey[df_join_placekey.placekey.isnull()].shape[0]*100/total_recs))
print("records missing a query_id: {0} | {1:.2f}% ".format(df_join_placekey[df_join_placekey.query_id.isnull()].shape[0], df_join_placekey[df_join_placekey.query_id.isnull()].shape[0]*100/total_recs))
Determine number of unique Placekeys
Placekey is able to map all of the addresses to their respective Placekeys no matter how the user input was typed in.
Below you will see how many of these address inputs were similar, yet different enough it cause a headache to try and do this without Placekey
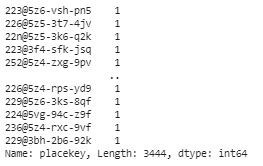
# Check the value counts of our Placekey column to find out if we have any repeating locations
vc = df_join_placekey.placekey.value_counts()
vc[vc > 1]
We can take a look at the top 2 and see how their addresses inputs stack up:
"222@3bt-b8t-swk"
"224@3bt-byd-r49"
Note: Since we do not have POI names, just addresses, our Placekey on returns the Address Encoding from the WHAT portion of our Placekey