Product updates, industry-leading insights, and more
The Ultimate Guide to Address Matching: Methods & How to Do It
by Placekey
Address matching seems like a simple enough task; all you need to do is verify address data and ensure that the physical location corresponds with the correct address records. In practice, however, address matching is extremely complicated, resulting in a number of challenges.
From spelling to formatting, people input addresses very differently. Not to mention, some databases use different formats for recording address data. This makes comparing and matching addresses across databases much more complicated than it would seem at face value.
Luckily, we’re here to teach you everything you need to know about address matching, so that you can leverage this for your business to improve shipping, billing, and more. In this article, we’ll cover the following:
What is address matching?
Common address matching problems ruining your data
3 address matching methods & approaches you can take
Do you need address matching software or should you build your own?
5 reasons not to use legacy systems for address matching
First, let’s review what address matching is and why it’s important. From there, we can discuss how you can benefit from it, and the different methods that you can use.
What is address matching?
Address matching (or geocoding) is the process of assigning physical location coordinates to addresses in a database. This allows you to pair a physical location with address records, ensuring that you are referring to the same place. Address matching is commonly used when a company ships products or for lead outreach.
Address matching and geocoding are the same thing, and can be used synonymously. Address matching is often incorrectly used synonymously with address verification and standardization, so many of these solutions actually validate, standardize, and match addresses. While these are all very closely related, they are slightly different.
Let’s cover the main differences before proceeding:
Address Verification: Verifies an address against an authoritative database (like USPS in the US) to ensure it is valid.
Address Standardization: Correct an incorrect address to a standardized format, based on an authoritative database (like USPS in the US).
These often go hand-in-hand, as you would typically attempt to validate an address, and if invalid, you would attempt to match or standardize it. For this reason, address verification, address standardization, and address matching are inherently related, and are often referred to interchangeably.
Common address matching problems ruining your data
Address matching should be simple enough; all you need to do is stack up two addresses next to each other, and compare them for a match, right? Unfortunately, there are a number of problems that can make matching addresses challenging.
Here are the most likely issues you’ll run into while trying to match addresses:
1. Input errors made by users
In many cases, addresses are input incorrectly by users, including misspellings, missing spaces, incorrect labels (“Street” vs “Road”), abbreviation formats (“St” and “Rd”), synonyms, and more. All of these make it difficult to have standardized data within a single database, let alone across multiple databases.
Below are some of the most common input errors:
Misspelling: 123 Maain Street
Missing Space: 123Main Street
Incorrect label: 123 Main Road
Abbreviation: 123 Main St
Tokenization: Main St 123
While these errors may seem easy to notice at a glance, it is very challenging to program a system to identify each difference. More than that, it requires significant computational power, and will take a lot of time to process. These errors can lead to significant errors when attempting to perform address matching, as the records will not match.
2. Not being able to link two datasets together
When you cannot relate two addresses (for all of the reasons we discussed above) you cannot connect your data. When this occurs, you end up with the following disparities between your records:
As you can see, address matching is made very complicated when you are comparing records that are often formatted and input differently. Because of this, it makes a simple task of matching addresses much more complicated than predicted. Difficulty pairing your datasets is critically important because:
Sales teams will be unable to determine what regions customers are located in
Marketing teams cannot link customers with mailing databases to send information via mail
Finance departments cannot send bills because customer address data doesn’t match
City planners cannot send notices to homeowners affected by zoning changes
Insurance companies cannot see where risk is located before a natural disaster
Issues with linking datasets will cause major issues with your workflow, slowing up your business and causing errors in delivery, billing, and more. Linking datasets properly is essential for making address matching work effectively and efficiently, and will take a bit of work to ensure you do it properly.
3. Failing to preprocess your data correctly
Cleaning your data before processing is essential for getting quality results. At the same time, this can save you significant processing time, as your results will compare easier and with greater accuracy. It may seem like an additional, tedious step, but it can greatly impact the outcome and is well worth the effort.
Convert addresses to lowercase
One of the main ways we can do this is by converting all characters to lowercase before processing. That way, we turn this:
As you can see, this makes it significantly easier to find a match that could otherwise be missed, since the two strings are both being compared in lowercase. This way, if someone has input a record with the incorrect case on a letter, the strings will still come back a match.
Convert terms to a single format
The second big thing to account for when preprocessing your data is the format. For addresses, this is especially important when it comes to street labels (i.e. “Street” vs “St” and “Avenue” vs “Ave”). Different records will use different standardized formats for addresses, and these will often vary when comparing two databases.
To limit the chance of errors, convert these terms to a standard format, and then compare. This will greatly increase your chance of a match, as well is reduce processing time.
Parse your data for easier matching
Despite standardized formats, it is extremely common for address components to be input out of order. There are two main methods of parsing your data to improve the chances of getting an accurate match:
Tokenization: Involves parsing the input string and separating out each unique component of the address, such as the number, locality, town name, and postal code. Each component can then be compared on it’s own, making it easier to match your addresses.
Concatenation: Involves joining of pre-existing tokens to produce a full address string. Components are combined to create a standardized address format that can then be compared against other datasets.
These methods are essentially the opposite of each other, so you will need to choose one or the other. Once you’ve selected your method for parsing your addresses, you can use coding to set up a parsing algorithm, which will allow you to set up rules for address parsing.
4. Processing these algorithms requires significant computational power
Although you can automate address matching using scripts, these algorithms still require a decent amount of computational power - and time - to run. Manually matching addresses is actually simpler in some ways, as your eyes are trained to identify differences.
For the human eye, it is relatively easy to identify that record 18763 and A1278 match, despite a few major spelling and formatting differences:
Reviewing this visually, you can still easily tell these are the same location. However, this visual review cannot currently be replicated using scripts. With a script, each character needs to be compared, and they need to be processed one at a time. Your data often needs to be preprocessed beforehand as well.
At the very least, this helps you visualize the frequency and extent of address formatting errors. You can also begin to understand why an address matching logic would have difficulty matching addresses, and why they frequently run into errors.
3 address matching methods & approaches you can take
While there are many different customizations you can make to your solutions, there are only a few main methods to use. Below are the 3 best methods of address matching:
1. Web service / API
Using an API or web service is one of the best ways to perform address matching. By linking your system to an authoritative database via an API, you can easily exchange and verify address data. For example, by using an address validation API that connects with the USPS, you can validate email addresses according to their authoritative database. This ensures that you are always using the most up-to-date, accurate version of an address.
APIs are simple and easy to use; pairing two systems for easier integration. Placekey performs a scrub on load, connecting with APIs to identify any changes or updates. This ensures that all Placekey address data is current and up-to-date.
2. Running scripts like Python, SQL, or Fuzzy address matching
Running scripts is a great way to perform address matching, as it automates much of the process for you. You can establish your own thresholds for determining a match, allowing you to customize the script you run for best results. You can do this using Python, SQL, and other programming languages, and you can use different methods, the most prominent of which is fuzzy logic address matching.
You can program your address matching solution to convert to lowercase for better matching, and use the Levenshtein distance to help you use fuzzy logic and determine partial matches.
Str1 = “Apple Inc.”
Str2 = “apple Inc”
Distance = levenshtein_ratio_and_distance(Str1.lower(),Str2.lower())
print(Distance)
Ratio = levenshtein_ratio_and_distance(Str1.lower(),Str2.lower(),ratio_calc = True)
print(Ratio)
The strings are 1 edits away
0.9473684210526315
Popular programming languages like Python and SQL already have address matching scripts developed by other users. Simply install and use these scripts, customizing them slightly for your own purposes. Using scripts enables flexibility and freedom when performing address matching, as you can set your own thresholds and determine what comes back a match.
3. Using brute force or the manual approach
One of the easiest ways to perform address matching is using a simple string matching algorithm, called the Brute Force algorithm. This algorithm attempts to match the first character of a pattern with the first character of text. If this succeeds, it attempts to match the second character, and so on. Once a match is not met, the pattern is slid over one character, and the process starts again.
The Brute Force algorithm is one of the most basic ways of performing string matching, and is very similar to what would occur in a manual review, where a person would review both strings for any errors.
In Java, the Brute Force method can be represented using:
for (int i = 0; i < n-m; i++) {
int j = 0;
while (j < m && t[i+j] == p[j]) {
j++;
}
if (j == m) return i;
}
System.out.println(‘‘No match found’’);
return -1;
As you can see, this is similar to how you would manually process this, one character at a time. Visually, we can process this information faster, but the same principle applies. Brute Force and manual review would both require hefty processing, which will take a decent amount of time - and can still come back with errors.
Do you need address matching software or should you build your own?
Using an address matching software will save you the time of building one yourself, but will also limit your capabilities. By building your own matching logic, you will have more flexibility and control over functionality and design. To build your own, you will also need some expertise and experience.
Legacy address matching software solutions perform the function of matching addresses (or geocoding), assigning physical coordinates to addresses in an authoritative database. Most of these solutions validate, standardize, and then match addresses, ensuring accuracy and avoiding errors.
While legacy solutions are designed to perform these essential address matching functions, they are often not optimized for integration or the flexibility you need. Alternatively, you can build your own solutions using Python, SQL, or other programming languages. This can give you more control over your address matching capabilities, but will require more upkeep and management.
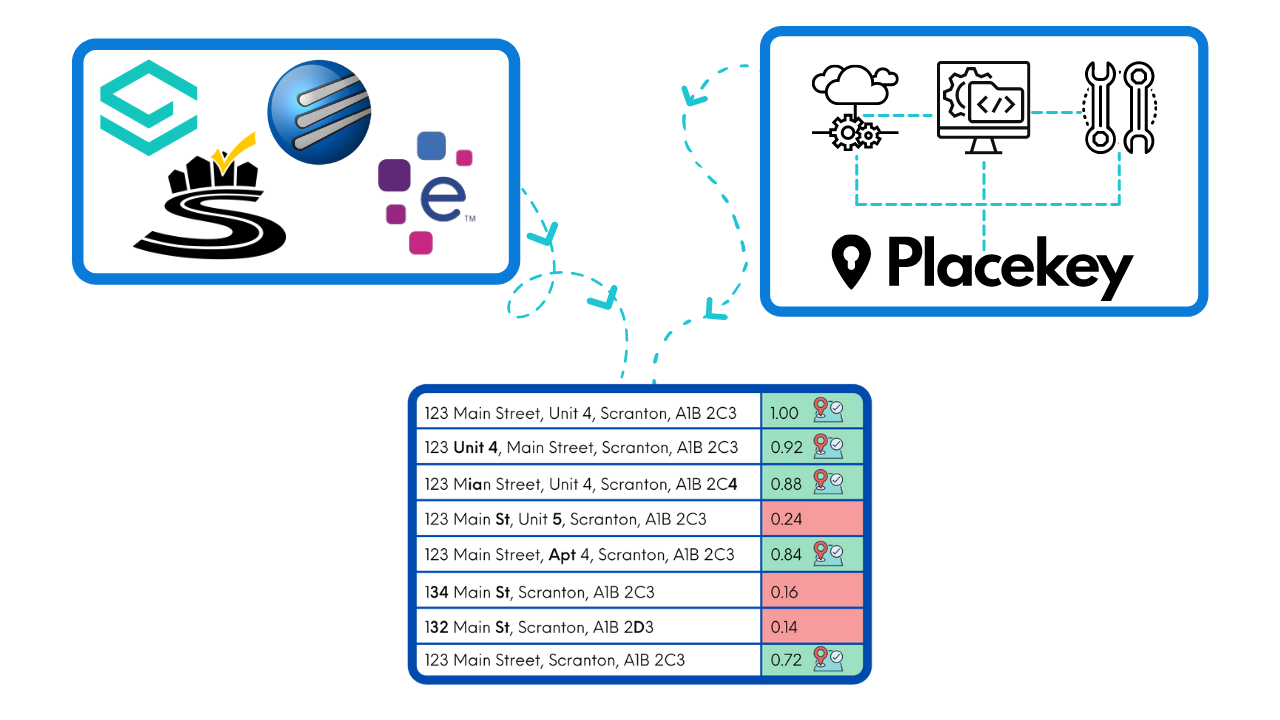
Using legacy software will be limiting and using SQL or Python will require significant experience and knowledge. Instead, you can use Placekey’s universal identifier, eliminating the need for address matching software altogether. You can create Placekeys yourself and leverage the network of existing Placekeys - all of which have been verified and matched previously.
You need address matching software when...
You need to validate shipping addresses: If you are shipping items, you will need to verify addresses according to an authoritative database (typically USPS in the US) prior to sending out your shipment.
Using restrictive integrations: Depending on the integrations you currently use, you may need to use a compatible address matching software, which could limit your options.
You want a restricted solution: If you want a solution that functions in the exact way it was designed — with no ability for modifications or customization — you may want to use a legacy software.
You don’t have a qualified team to build one: While building your own logic is not overly complicated, having accurate results is extremely important. If your team is not qualified to build out your own, you will likely want to rely on a legacy address matching software.
Legacy address matching software will require installation and integration, but will come basically ready-to-use. They are designed for the purpose of matching addresses, and will verify and standardize addresses in the process. However, these are often rigid and come with set restrictions that you will need to work within (or work around).
You need to build your own address matching logic when…
You want flexibility and freedom: Building your own solution means being able to design to your specifications, giving you more control over the algorithm itself and the comparisons made.
You want to control the speed of processing: By controlling the threshold and setting up your own solution, you are able to control how many items are compared, in turn controlling the processing speed.
You have a qualified team to build one: To build an effective, efficient matching logic, you will need a team with the right experience and skills for the job.
Building your own address matching logic will give you the freedom and flexibility to develop it specifically for your needs, which will make it easier to use on a day-to-day basis, while also improving results. However, it will require significant upfront work to build and regular upkeep and maintenance to maintain.
Ultimately, whether you should build your own or rely on a legacy address matching software will depend on your needs and intended outcome. If neither of these sounds ideal, Placekey has an alternative solution: a universal identifier that encodes location, address, and POI data into a single Placekey. These keys are not subject to phonetic, spelling, or formatting errors, as they use standardized formatting.
5 reasons not to use legacy systems for address matching
When choosing a solution, it may seem easiest to select an existing legacy address matching software, and while these may work for you, you should compare all your options before choosing to go with a legacy system.
They are rarely open-source, which limits their use inside your applications: Legacy address matching solutions are almost never open-source, and are therefore much less flexible and open to modification. In some cases, they are very restrictive to use.
Does not use key-based linking: Key-based linking enables simple connection of two resources, with one key to refer to both. Traditional software does not use key-based linking, meaning you need to cross-reference record databases.
Cannot encode multiple places to a single address: Addresses do not contain location information, and when pairing a POI with an address, you will always need to cross-reference information in different databases. You can therefore not encode multiple places to a single address efficiently.
Expensive to purchase and upkeep: Legacy solutions are expensive to buy and install, and they cost a significant amount in management. This includes training your team and working with a vendor that provides this service to you.
Limited connectivity and integration opportunities: Legacy solutions for address matching are much more rigid, making it difficult to connect them with other integrations, such as APIs and SDKs. In some cases, you will be restricted to specific solutions that can pair with the legacy matching software you are using.
If the rigid nature of legacy address matching software sounds too limiting and creating your own solution seems like an insurmountable challenge, you may want to use Placekey instead! Placekey is a universal identifier for physical locations that encodes location, address, and POI information in an alphanumeric code.
Learn more about how Placekey works and why you should use it instead of traditional address matching software. With Placekey, address matching is unnecessary, as you can easily and conveniently find, share, and create reliable location and address data.
Placekey
Placekey is the universal standard identifier for a physical place. Learn more about us at Placekey.io.
Get ready to unlock new insights on physical places

.png)